
Kurzbeschreibung
Der Kunde wandte sich mit einer Herausforderung an uns: Die Datenbankschicht eines großen, seit vielen Jahren im Einsatz befindlichen Systems sollte modernisiert werden. Das Ziel war klar, aber anspruchsvoll – die alte Datenbank-Engine sollte ersetzt werden, ohne die Anwendungslogik zu verändern oder den laufenden Betrieb zu beeinträchtigen.
Gemeinsam mit dem Kunden haben wir:
- eine maßgeschneiderte Migrationsstrategie entwickelt,
- die passende Datenbanktechnologie ausgewählt,
- einen dedizierten Datenkonverter erstellt und
- das System so angepasst, dass es mit der neuen Komponente reibungslos funktioniert.
Heute nutzt das System eine moderne NoSQL-Datenbank – schneller, wartungsfreundlicher und ohne Ausfallzeiten oder Funktionsänderungen.
Kunde
Der Kunde ist ein Softwareanbieter im Gesundheitswesen, der innovative Produkte in der DACH-Region anbietet.
Problem
Der Kunde beauftragte uns, die Datenbankschicht des Systems zu modernisieren.
Die bestehende Lösung basierte auf einer rund dreißig Jahre alten Objektdatenbank-Engine, die sowohl technologisch als auch wirtschaftlich ineffizient geworden war.
- Die Technologie unterstützte keine inkrementellen Updates – jedes Update erforderte die Auslieferung einer kompletten Datenbank an die Endkunden.
- Inzwischen waren die Datenbankdateien sehr groß (≈ 60 GB), was Übertragungen langsam, fehleranfällig und teuer machte.
- Der Anbieter der Tools zum Erstellen und Bearbeiten der Datenbanken erhöhte zudem die Lizenzpreise, wodurch neue Installationen wirtschaftlich unrentabel wurden.
Um neue Kunden zu gewinnen, musste der Kunde also eine der zentralen Systemdatenbanken auf eine moderne Technologie umstellen.
Herausforderung
Der Austausch einer Datenbank in einem so großen System ist ein komplexer Prozess. Der Kunde wollte, dass das System weiterhin exakt so funktioniert wie bisher – nur mit einer effizienteren und kostengünstigeren Datenbanktechnologie.
Daraus ergaben sich vier zentrale Fragen:
- Welche neue Datenbanktechnologie erfüllt die Anforderungen des Kunden und löst die bestehenden Probleme?
- Wie lässt sich nur die Datenbank austauschen, ohne die Systemarchitektur grundlegend zu verändern?
- Wie kann man die Altdatenbanken auf die neue Technologie migrieren, ohne Informationen zu verlieren?
- Wie kann das Update durchgeführt werden, ohne den Betrieb für Endnutzer zu unterbrechen?
Lösung
Wir gehen solche Herausforderungen ohne vorgefertigte Antworten an. Zuerst stehen die geschäftlichen Ziele im Fokus, danach folgt die Auswahl der passenden Technologie.
Schritt 1: Auswahl der Datenbanktechnologie
Die erste Aufgabe bestand darin, eine neue Technologie auszuwählen.
Bei der Analyse der Optionen berücksichtigten wir die Gründe, weshalb der Kunde uns beauftragt hatte:
- Der bisherige Anbieter hatte die Preise erhöht und so das Wachstum gehemmt.
- Die Objektdatenbank war für inkrementelle Datenupdates ungeeignet – jede Änderung erforderte die Übertragung der gesamten Datenbankdatei, was Leistung und Kosten belastete.
Die Gesamtkosten der Lösung waren entscheidend, daher musste die neue Technologie wirtschaftlich rentabel sein. Open-Source-Optionen boten sich daher natürlich an.
Aus einer Vielzahl möglicher Alternativen suchten wir eine Lösung, die stabil, performant und zugleich flexibel in der Schema-Definition ist – mit effizienten inkrementellen Schreibvorgängen.
Nach sorgfältiger Abwägung entschieden wir uns schließlich für eine Open-Source-Dokumentdatenbank.
Warum?
- Flexible Schemas, die sich natürlich aus Objektmodellen ableiten lassen
- Unterstützung inkrementeller Updates – nur Änderungen werden übertragen, nicht ganze Datenbankdateien
- Hohe Leistung bei großen, heterogenen Datensätzen
- Leistungsfähige Abfragemöglichkeiten (Filter, Aggregationen, Volltextsuche)
- Zuverlässige Skalierbarkeit in verteilten Umgebungen
Kurz gesagt: Die gewählte Datenbank ermöglicht einfachere Updates, schnellere Iterationen, geringere Kosten und unterstützt das weitere Wachstum des Systems.
Schritt 2: Migration von der Objekt- zur Dokumentdatenbank
Nach der Technologieentscheidung folgte ein Fail-Fast-Vorgehen, um sowohl die Wahl als auch die Durchführbarkeit der Migration von einer Objektdatenbank zu einem Document Store rasch zu validieren.
Gemeinsam mit dem Kunden wählten wir eine mittelgroße Datenbank und entwickelten einen dedizierten Konverter, der:
- Daten aus der alten Objektdatenbank liest,
- sie in ein dokumentorientiertes Format umwandeln,
- sie in die neue Dokumentdatenbank schreibt.
Der Prozess lief in mehreren Stufen ab: Der Konverter rief Objekte und deren Beziehungen ab und transformierte sie entsprechend eines abgestimmten Mappings: Einige Strukturen wurden direkt in Dokumente eingebettet, andere als Referenzen zwischen Collections abgebildet.
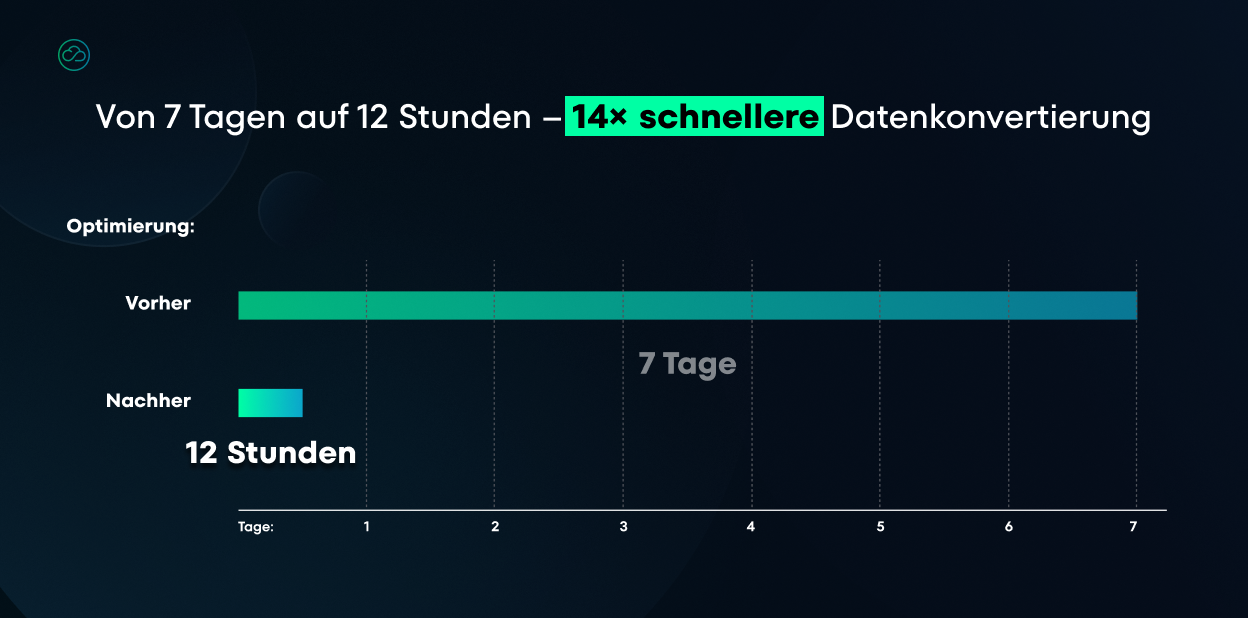
Das war nicht akzeptabel – daher nahmen wir gezielte Optimierungen vor und reduzierten die Dauer auf nur zwölf Stunden. Darauf sind wir ehrlich gesagt ziemlich stolz.
Das Tool übernahm auch Typkonvertierungen, erzeugte neue IDs, wo nötig, und teilte große Strukturen auf, um die Grenzwerte der NoSQL-Datenbank-Engine einzuhalten. Wegen der Datenmenge lief die gesamte Operation in Batches, um Speicherverbrauch und Fortschritt kontrollieren zu können.
Die Testmigration verlief reibungslos: Die Daten wurden fehlerfrei übertragen, es traten keine Probleme bei der Typkonvertierung auf. Dies bestätigte, dass die gewählte Datenbanktechnologie optimal zu den Systemanforderungen passte.
Der erfolgreiche Test führte anschließend zur vollständigen Migration der gesamten Datenbank auf die neue Technologie.

Schritt 3: Austausch der Datenbank im System
Nachdem die neue Datenbank bereitstand, passten wir das System an, um die neue Datenbank-Engine zu nutzen.
Die gute Nachricht: Das System verfügte bereits über eine Abstraktionsschicht für den Datenzugriff, die Geschäftslogik und Datenbank trennte – und diese war größtenteils konsequent umgesetzt (mit wenigen direkten Datenbankaufrufen).
Das Datenmodell war in Java-Klassen implementiert, die jedoch auf Schnittstellen und Basisklassen des alten Datenbanktreibers angewiesen waren. Diese Abhängigkeiten zu entfernen, war Teil unserer Aufgabe.
Zunächst führten wir ein Audit aller Stellen durch, an denen das System mit der alten Datenbank kommunizierte. Darauf basierend definierten wir saubere Schnittstellen zwischen Anwendungslogik und Datenspeicherung
Dann implementierten wir diese Schnittstellen für die neue NoSQL-Datenbank – unter Nutzung fortgeschrittener Java-Mechanismen wie Reflection und aspektorientierte Programmierung.
So konnten wir Änderungen im bestehenden Code minimal halten und die Geschäftslogik nahezu unverändert lassen.
Luke Warchal
CTO @NubiSoftDie größte Herausforderung war, das Verhalten der alten Engine exakt nachzubilden – insbesondere bei Such- und Sortierfunktionen, damit das System mit der neuen Datenbank identisch reagierte.
Automatisierte Tests waren hier entscheidend: Wir ließen sie parallel auf beiden Versionen laufen und korrigierten Abweichungen sofort.
Unser Vorgehen folgte dem Prinzip: “Make It Work. Make It Right. Make It Fast.”
Zuerst integrierten wir die neue Datenbank in einige UI-Ansichten. Mit Feedback aus manuellen und automatisierten Tests beseitigten wir Fehler und Sonderfälle. Anschließend optimierten wir die Performance – mithilfe eines Profilers wurden Performance-Engpässe identifiziert, woraufhin die entsprechenden Codepfade optimiert wurden. Basierend auf den realen Lese- und Schreibmustern wurde zudem Caching implementiert, um die Effizienz weiter zu steigern.
Nachdem Funktionsgleichheit und Leistungsanforderungen erreicht waren, starteten wir die Deployments: Die neue App-Version stand ab sofort für Neukunden bereit, während bestehende Installationen gestaffelt migriert wurden – zuerst die neueren (kleinere Datenmengen, geringeres Risiko), später die älteren (größere Datenmengen, höherer Aufwand).
So blieb der Prozess kontrolliert und störungsfrei.
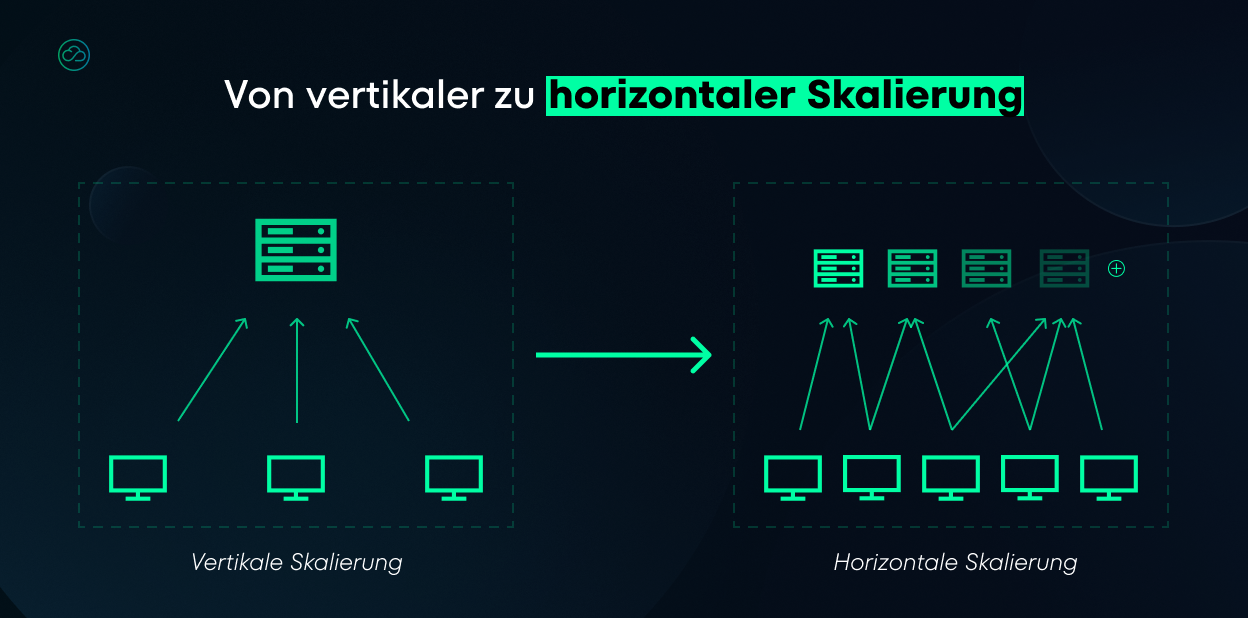
Die von uns entwickelte Lösung beeinflusste die gesamte Systemarchitektur und ermöglichte horizontales Skalieren auf Seiten des Endkunden.
Erkenntnisse
In diesem Projekt entwickelten wir praxisbewährtes Know-how für die Migration von einer Objektdatenbank zu einem Dokumenten-Store – bei durchgehendem Systembetrieb.
- Nutzung einer bestehenden Datenzugriffsabstraktion in Legacy-Systemen
Wir entwickelten einen Ansatz, der die vorhandene Abstraktionsschicht nutzt und einen Adapter für die neue Engine bereitstellt. Dadurch blieben Codeänderungen minimal und das Risiko, Fehler in die Anwendungslogik einzuschleusen, gering. - Reproduzierbare Migrationspipeline (Objekt-DB ➝ Dokumenten-DB)
Wir erstellten einen Offline-Java-Konverter mit klar definiertem Datenmodell-Mapping (Einbettung/Referenzierung), Typkonvertierungen, ID-Erzeugung und Batch-Verarbeitung großer Datenmengen. Diese Tools und Verfahren können für zukünftige Installationen wiederverwendet werden. - Operational Playbook für große On-Premise-Migrationen
Wir sammelten praktische Erfahrung mit Migrationen während Wartungsfenstern, Fortschrittsüberwachung, Ergebnisvalidierung und vorbereiteten Rollback-Szenarien – mit Fokus auf Servicekontinuität und minimaler Ausfallzeit.
Wenn Sie vor einer ähnlichen Herausforderung stehen, zeigen wir Ihnen gern,
wie Sie eine Datenbank in einem laufenden Produktivsystem ersetzen können – mit minimalen Änderungen an der Anwendungslogik und ohne Ausfallzeiten.
Das könnte Sie auch interessieren:


